平时做 JS 逆向、自动化开发,最耗费时间的不是写代码,而是调试适配、细节排错。经常一个小问题卡一整天,这也是很多新手劝退的主要原因。
顺带解答一个行业现象:早年泛滥的软件注册机、短信轰炸机,如今几乎销声匿迹。核心原因就是网站前端安全风控全面升级。
其中对自动化最致命的防护就是验证码拦截,普通脚本模拟登录、接口请求极易被风控拦截,纯自动化脚本没有识图能力,根本无法突破验证。

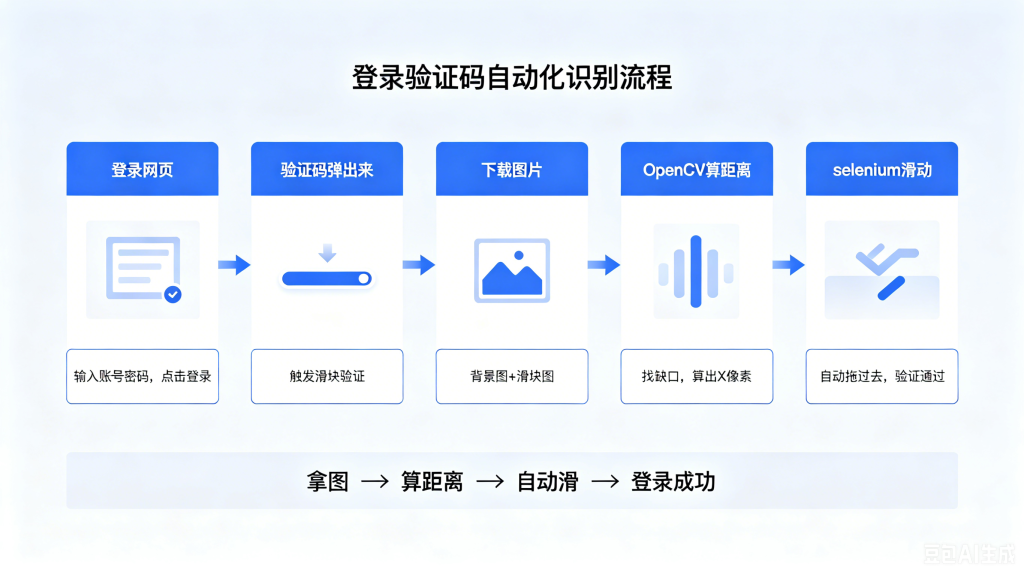
今天这篇教程,带大家从零实现 Selenium+OpenCV 全自动识别滑动验证码、模拟人工登录,以豆瓣滑动验证码为实战案例,全程通俗易懂,零基础也能看懂。
新手友好提示:如果从没学过 Selenium 和 OpenCV,不用慌,两个库入门极其简单,可直接打开官方文档快速熟悉基础用法:
Selenium 官方文档:https://www.selenium.dev/documentation/
OpenCV 官方文档:https://docs.opencv.org/
本文目录
- 技术栈详解:分工与核心作用
- 前期准备:环境安装与驱动配置
- 实战步骤1:启动浏览器,规避自动化风控
- 实战步骤2:模拟人工操作,触发验证码
- 实战步骤3:提取验证码图片,解决尺寸偏差问题
- 实战步骤4:OpenCV图像识别,计算滑动距离
- 实战步骤5:模拟真人轨迹滑动,完成验证
- 完整可运行整合代码
- 常见报错与排错指南
- 技术总结与方案拓展
一、技术栈详解:分工与核心作用
整套自动化破解方案,仅依赖两个核心库,分工明确、解耦清晰,没有复杂冗余逻辑:
Selenium(浏览器自动化工具)
- 核心作用:操控真实浏览器,1:1 模拟人类操作(打开页面、点击、输入、拖拽、等待)
- 核心优势:基于原生浏览器运行,可规避绝大多数基础反爬、设备检测、UA 风控,比纯接口脚本隐蔽性更强
OpenCV(cv2 计算机视觉库)
- 核心作用:图像处理、边缘检测、模板匹配、缺口定位
- 核心优势:替代人眼识别验证码缺口,精准计算滑块需要滑动的像素距离,是破解滑动验证码的核心
整体闭环流程
Selenium 打开登录页 → 自动输入账号密码触发验证码 → 提取验证码图片链接 → OpenCV 识图算滑动距离 → Selenium 模拟真人拖拽完成验证。
二、前期准备:环境安装与驱动配置
2.1 安装依赖库
打开终端/CMD,执行以下命令,一键安装所有所需模块:
pip install selenium opencv-python requests2.2 Chrome 驱动配置(高频踩坑点)
Selenium 无法直接操控浏览器,必须匹配对应版本的驱动,步骤如下:
- Chrome 地址栏输入
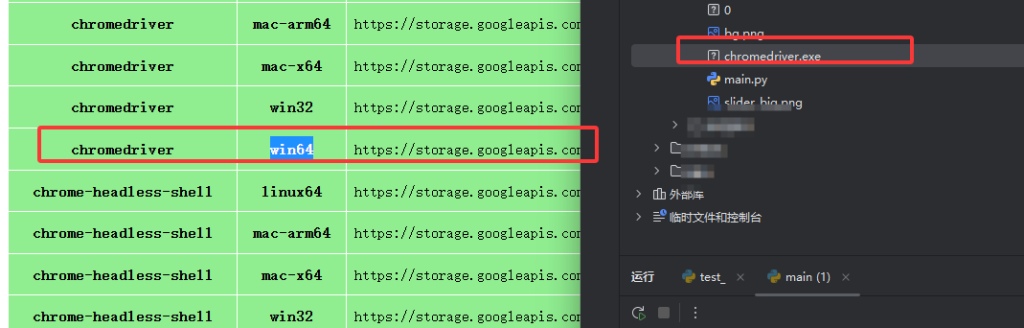
chrome://version/,查看本地浏览器版本 - 访问驱动官网:https://googlechromelabs.github.io/chrome-for-testing/,下载对应版本
chromedriver-win64.zip - 解压后,将
chromedriver.exe和 Python 脚本放在同一文件夹,否则会报驱动找不到错误
三、实战步骤1:启动浏览器,规避自动化风控
直接运行 Selenium 会被网站识别为自动化工具,触发风控拦截。必须先配置参数,隐藏浏览器自动化特征。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# 屏蔽自动化检测特征
options = Options()
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
# 启动浏览器并打开豆瓣登录页
driver = webdriver.Chrome(options=options)
url = "https://www.douban.com/login"
driver.get(url)核心作用:消除浏览器自动化标识,让脚本行为和普通用户手动打开浏览器完全一致。
四、实战步骤2:模拟人工操作,触发验证码
通过定位页面元素,模拟人工切换登录、输入账号密码、点击登录,主动触发滑动验证码。
import time
from selenium.webdriver.common.by import By
time.sleep(2)
# 切换密码登录标签
driver.find_element(By.CLASS_NAME, "account-tab-account").click()
time.sleep(1)
# 输入账号密码(自行替换为自己的账号)
driver.find_element(By.NAME, "username").send_keys("你的账号")
driver.find_element(By.NAME, "password").send_keys("你的密码")
time.sleep(1)
# 点击登录,触发滑动验证码
driver.find_element(By.CLASS_NAME, "btn-account").click()
time.sleep(3)延时说明:代码中 time.sleep() 是模拟人工操作间隔,极速操作会被判定为机器行为,触发风控。
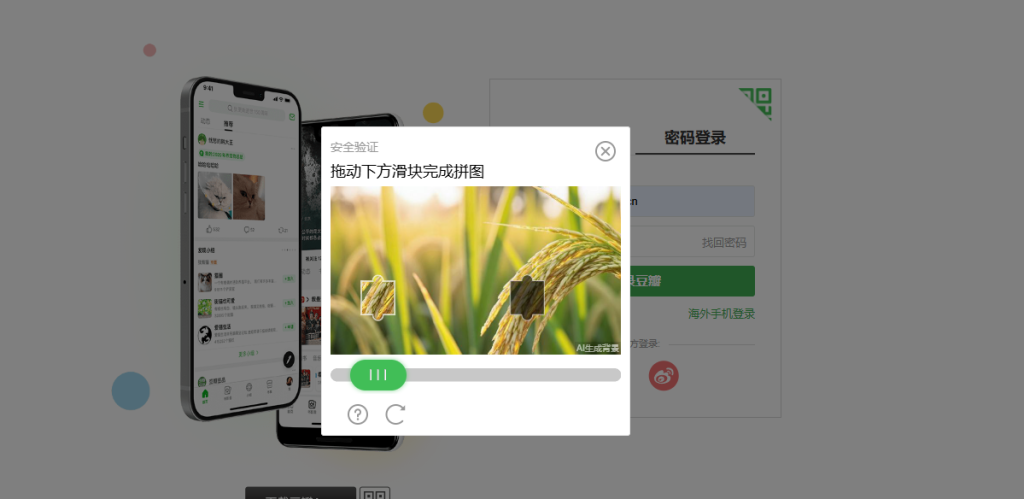
五、实战步骤3:提取验证码图片,解决尺寸偏差问题
豆瓣滑动验证码分为背景缺口图和滑块图,图片链接隐藏在元素 style 样式中,需要手动解析提取。
5.1 解析图片链接代码
def extract_url_from_style(style):
if 'url("' in style:
return style.split('url("')[1].split('")')[0]
return None
# 定位两张验证码图片元素
bg_elem = driver.find_element(By.XPATH, '//*[@id="slideBg"]')
slider_elem = driver.find_element(By.XPATH, '//*[@id="tcOperation"]/div[9]')
# 提取图片URL
bg_url = extract_url_from_style(bg_elem.get_attribute("style"))
slider_url = extract_url_from_style(slider_elem.get_attribute("style"))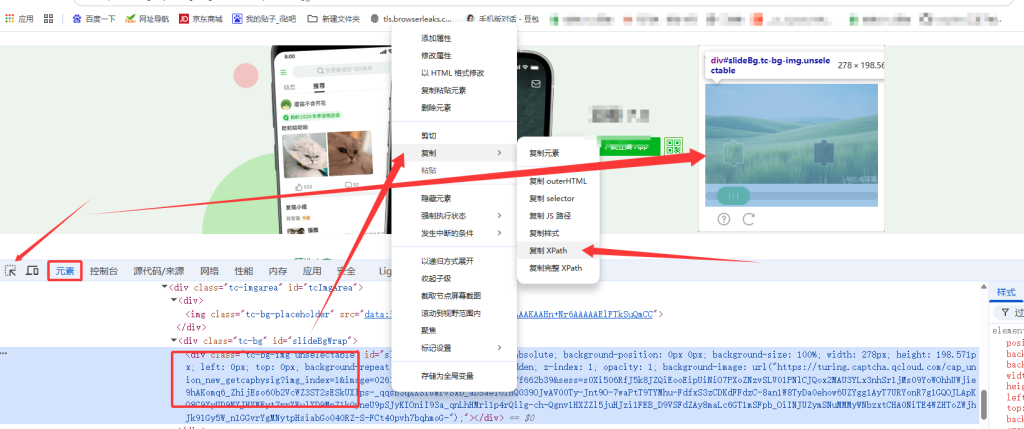
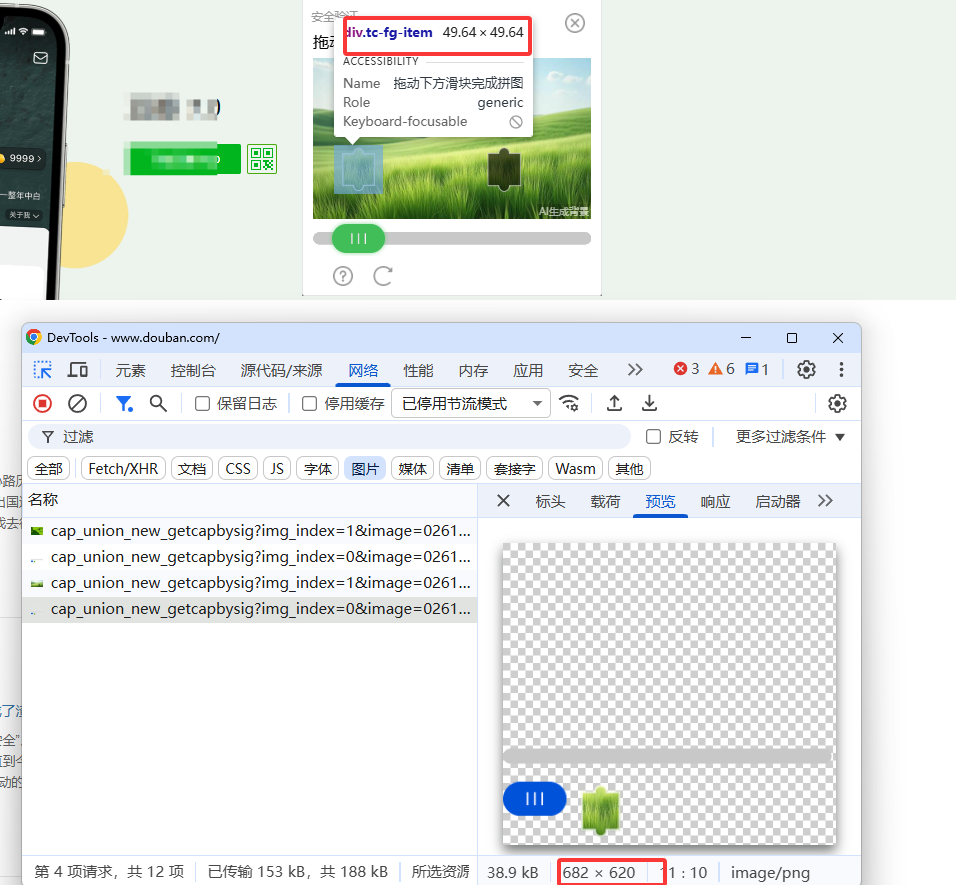
5.2 核心难点:尺寸不匹配问题
这是新手最大踩坑点:网页展示图片 ≠ 原始图片尺寸,直接识别会出现巨大偏差:
| 图片类型 | 原始尺寸 | 网页展示尺寸 | 缩放比例 |
|---|---|---|---|
| 背景图 | 672×390 | 278×198 | 约 0.413 |
| 滑块图 | 682×620 | 49×49 | 约 0.072 |
解决方案:基于原始大图做图像识别,最后按比例换算为网页滑动距离,同时精准裁剪滑块有效区域。
5.3 下载验证码图片到本地
import requests
with open("bg.jpg", "wb") as f:
f.write(requests.get(bg_url).content)
with open("slider.png", "wb") as f:
f.write(requests.get(slider_url).content)六、实战步骤4:OpenCV图像识别,计算滑动距离
核心算法模块:通过灰度处理、边缘检测、模板匹配,精准定位缺口位置,计算最终滑动像素。
import cv2
def get_distance(bg_path, slider_path):
# 1. 读取图片,滑块图保留透明通道
bg = cv2.imread(bg_path)
slider_big = cv2.imread(slider_path, cv2.IMREAD_UNCHANGED)
# 2. 精准裁剪有效滑块区域
slider = slider_big[490:610, 140:260]
# 3. 提取滑块透明轮廓,去除背景干扰
slider_alpha = slider[:, :, 3]
# 4. 图片灰度化+边缘检测,突出轮廓
bg_gray = cv2.cvtColor(bg, cv2.COLOR_BGR2GRAY)
bg_edge = cv2.Canny(bg_gray, 200, 300)
slider_edge = cv2.Canny(slider_alpha, 200, 300)
# 5. 核心:模板匹配,寻找最优缺口位置
match_result = cv2.matchTemplate(bg_edge, slider_edge, cv2.TM_CCOEFF_NORMED)
_, _, _, max_pos = cv2.minMaxLoc(match_result)
# 6. 计算原图缺口中心坐标
gap_x = max_pos[0] + 60
# 7. 比例换算为网页真实滑动距离
real_distance = gap_x * 278 / 672
# 8. 经验微调,修正渲染偏差
return int(real_distance) - 10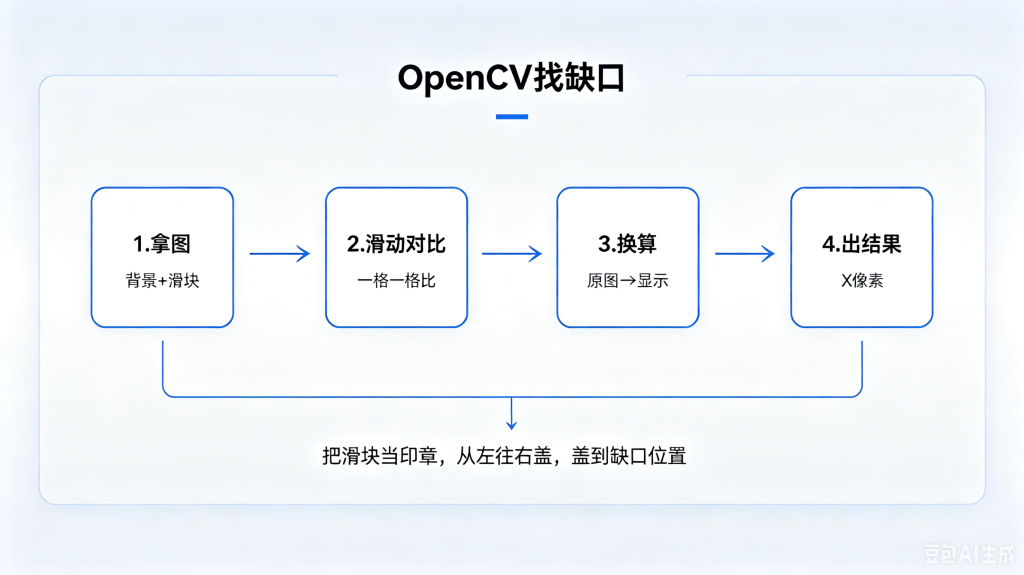
七、实战步骤5:模拟真人轨迹滑动,完成验证
重点:匀速滑动必被风控,必须模拟真人「先快后慢」的不规则拖拽轨迹,才能通过验证。
from selenium.webdriver import ActionChains
# 获取滑块按钮
slider_btn = driver.find_element(By.XPATH, '//*[@id="tcOperation"]/div[7]')
# 获取计算好的滑动距离
move_dist = get_distance("bg.jpg", "slider.png")
# 按住滑块
action = ActionChains(driver)
action.click_and_hold(slider_btn).perform()
time.sleep(0.5)
# 模拟真人分段滑动
current = 0
mid = move_dist * 4 / 5
while current < move_dist:
step = 5 if current < mid else 2
action.move_by_offset(step, 0).perform()
current += step
time.sleep(0.01)
# 松开鼠标,完成验证
action.release().perform()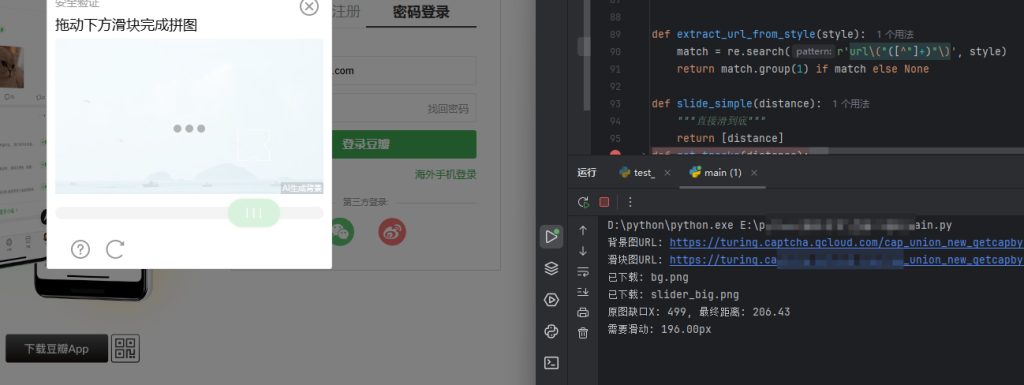
八、完整可运行整合代码
整合所有模块,增加异常捕获,开箱即用:
import re
import requests
import cv2
import time
import random
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.chrome.options import Options
def download_image(url, path):
headers = {"User-Agent": "Mozilla/5.0", "Referer": "https://www.douban.com/"}
resp = requests.get(url, headers=headers)
with open(path, "wb") as f:
f.write(resp.content)
print(f"已下载: {path}")
def get_distance(bg_path, slider_path):
"""
计算滑块需要滑动的距离
bg_path: 背景图(有缺口的大图,原图尺寸 672x390)
slider_path: 滑块大图(包含小滑块的完整图,原图尺寸 682x620)
"""
# ========== 1. 读取图片 ==========
bg = cv2.imread(bg_path) # 背景图,尺寸 672x390
slider_big = cv2.imread(slider_path, cv2.IMREAD_UNCHANGED) # 滑块大图,尺寸 682x620,保留透明通道
# ========== 2. 裁剪出小滑块 ==========
# 为什么是 490:610 和 140:260?
# 因为网页 CSS 里定义了滑块在屏幕上的显示位置和大小
# 通过比例换算,得出在原图上小滑块的位置是 x=140, y=490, 宽高=120x120
slider = slider_big[490:610, 140:260] # 从大图中切出 120x120 的小滑块
# ========== 3. 提取滑块的形状 ==========
# PNG图片有4个通道:R(红), G(绿), B(蓝), A(透明度)
# 取第4个通道(Alpha通道),白色=滑块形状,黑色=透明背景
slider_gray = slider[:, :, 3] # 只取透明度通道,得到滑块的形状轮廓
# ========== 4. 背景图处理 ==========
# 把彩色背景图转成黑白灰度图,去掉颜色干扰
bg_gray = cv2.cvtColor(bg, cv2.COLOR_BGR2GRAY)
# ========== 5. 边缘检测 ==========
# Canny 边缘检测:把图片中物体的边缘用白线标出来
# 参数 200,300 是高低阈值,值越大越敏感
bg_edges = cv2.Canny(bg_gray, 200, 300) # 背景图的边缘轮廓
slider_edges = cv2.Canny(slider_gray, 200, 300) # 滑块图的边缘轮廓
# ========== 6. 模板匹配(核心算法)==========
# 把滑块轮廓(slider_edges)作为模板,在背景轮廓(bg_edges)上滑动
# TM_CCOEFF_NORMED:归一化相关系数匹配法,结果值范围 -1 到 1
# 值越大说明越像,1=完全相同,0=无关,-1=完全相反
result = cv2.matchTemplate(bg_edges, slider_edges, cv2.TM_CCOEFF_NORMED)
# 找到结果中最大值的位置(即最匹配的位置)
# min_loc: 最小值位置, max_loc: 最大值位置
_, _, _, max_loc = cv2.minMaxLoc(result)
# ========== 7. 缺口在原图上的中心X坐标 ==========
left = max_loc[0] # 缺口左上角的 X 坐标
gap_original = left + 60 # 缺口中心X = 左上角X + 滑块宽度的一半(120/2=60)
# 公式1:缺口中心X = 匹配到的左上角X + 滑块宽度 ÷ 2
# gap_original = left + 60
# ========== 8. 换算到网页显示尺寸 ==========
# 原图宽度是 672px,但网页上显示的背景图宽度是 278px
# 需要按比例缩放,才能得到真实的滑动距离
display_width = 278 # 网页上背景图的显示宽度(固定值)
original_width = bg.shape[1] # 原图宽度 = 672
distance = gap_original * display_width / original_width
# 公式2:网页滑动距离 = 原图缺口X × (网页显示宽度 ÷ 原图宽度)
# distance = gap_original × (278 ÷ 672)
# distance = gap_original × 0.413
# ========== 9. 输出并返回 ==========
print(f"原图缺口X: {gap_original}, 最终距离: {distance:.2f}")
return int(distance) - 10 # 减10是经验微调,实际测试后加的偏移量
def extract_url_from_style(style):
match = re.search(r'url\("([^"]+)"\)', style)
return match.group(1) if match else None
def slide_simple(distance):
"""直接滑到底"""
return [distance]
def get_tracks(distance):
"""
生成仿人滑动的轨迹数组
原理:模拟人的拖动习惯 —— 先加速后减速
:param distance: 需要滑动的总距离(像素)
:return: 轨迹数组,每个元素是每次移动的偏移量(像素)
"""
tracks = [] # 存储每一步移动的距离
current = 0 # 当前已经移动的总距离
mid = distance * 0.6 # 加速阶段的终点(前60%加速,后40%减速)
t = 0.05 # 时间间隔(秒),越小轨迹越平滑
v = 0 # 初始速度(像素/秒)
# 循环生成轨迹,直到走完总距离
while current < distance:
# 根据当前位置决定加速度
# 前60%:加速(a=20),模拟人启动时加快速度
# 后40%:减速(a=-3),模拟人快到目标时减速
a = 20 if current < mid else -3
# 匀变速运动位移公式:s = v0 * t + 0.5 * a * t^2
s = v * t + 0.5 * a * t * t
# 累加位移
current += s
# 将本次移动距离取整后加入轨迹(像素必须是整数)
tracks.append(round(s))
# 更新速度:v = v0 + a * t
v += a * t
# 修正误差:因为取整可能导致总距离不等于目标距离
total = sum(tracks)
if total > distance:
# 如果超了,从最后一步减去多余的部分
tracks[-1] -= total - distance
elif total < distance:
# 如果不够,补一步剩余距离
tracks.append(distance - total)
return tracks
def slide(driver):
# 切换iframe
driver.switch_to.frame(0)
time.sleep(1)
n = 1
while n <= 5:
try:
# 获取背景图URL
bg_element = driver.find_element(By.XPATH, '//*[@id="slideBg"]')
style = bg_element.get_attribute("style")
bg_url = style.split('url("')[1].split('")')[0]
# 获取滑块大图元素(小方块那个)
elem = driver.find_element(By.XPATH, '//*[@id="tcOperation"]/div[9]')
style = elem.get_attribute("style")
big_url = extract_url_from_style(style)
print(f"背景图URL: {bg_url[:80]}...")
print(f"滑块图URL: {big_url[:80]}...")
# 下载图片
download_image(bg_url, "bg.png")
download_image(big_url, "slider_big.png")
# 计算距离
distance = get_distance("bg.png", "slider_big.png")
print(f"需要滑动: {distance:.2f}px")
tracks = slide_simple(distance)
# 找滑块元素
block = driver.find_element(By.XPATH, '//*[@id="tcOperation"]/div[7]')
# 1. 按下滑块
ActionChains(driver).click_and_hold(block).perform()
time.sleep(0.1)
# 2. 按轨迹滑动
for track in tracks:
ActionChains(driver).move_by_offset(xoffset=track, yoffset=random.uniform(-1, 1)).perform()
time.sleep(random.uniform(0.01, 0.02))
# 3. 松开滑块
ActionChains(driver).release().perform()
time.sleep(2)
# 4. 检查验证是否成功
# 如果验证成功,instructionText 会消失或变成其他状态
block = driver.find_element(By.XPATH, '//*[@id="tcOperation"]/div[7]')
n += 1
print(f"第{n - 1}次验证失败,重试...")
print(f"本次将会滑动:{distance}")
except:
print(f"第{n}次验证成功")
break
def main():
url = "https://www.douban.com/login"
options = Options()
options.add_argument('--disable-blink-features=AutomationControlled')
driver = webdriver.Chrome(options=options)
driver.get(url)
time.sleep(2)
# 点击密码登录
driver.find_element(By.CLASS_NAME, "account-tab-account").click()
time.sleep(1)
# 输入账号密码
driver.find_element(By.NAME, "username").send_keys("20761430@qq.com")
driver.find_element(By.NAME, "password").send_keys("wewewrqr")
time.sleep(1)
# 点击登录按钮
driver.find_element(By.CLASS_NAME, "btn-account").click()
time.sleep(3)
# 滑动验证码(内部会自动下载图片、计算距离、滑动)
slide(driver) # distance参数会被覆盖,随便传个0
time.sleep(3)
print("完成")
# driver.quit()
if __name__ == '__main__':
main()九、常见报错与排错指南
- 报错:找不到 chromedriver
解决:驱动版本与Chrome版本不匹配,或驱动文件与脚本不在同一目录。 - 问题:图片识别正常,滑动位置偏差
解决:微调get_distance函数末尾的-10经验偏移值,适配页面渲染误差。 - 问题:滑动完成仍验证失败
解决:优化滑动轨迹延迟,检查浏览器反检测配置是否完整。 - 问题:元素定位失败
解决:网站页面更新,重新F12抓取最新 XPath 和类名。
十、技术总结与方案拓展
方案核心总结
本方案采用 Selenium行为模拟 + OpenCV视觉识别 组合,完美适配绝大多数横向滑动验证码,规避基础风控,新手可快速上手。
温馨提示:本文技术仅用于个人学习、技术研究,请勿用于非法爬虫、批量注册等违规操作,严格遵守网络安全法律法规。