在完成《某鱼sign参数加密分析与本地复现》并成功逆向无数JS加密签名后,我们遭遇了一堵新的”叹息之墙”:请求在抵达服务器处理任何业务逻辑之前就被拒绝。当我们发现/h5/mtop.taobao.idlehome.home.webpc.feed/1.0接口在浏览器中畅通无阻,却在Python和apiPost中彻底失效时,一个明确的信号出现了——反爬虫的战场已经从应用层转向了网络层。
TLS指纹绕过成为了我们必须掌握的新技能。这背后,正是TLS指纹验证在发挥作用,它不再关心你发送的数据是否正确,而是审查你的身份是否合法。本文将带你穿透这层身份迷雾,并揭示这场攻防升级背后的深层逻辑。
本文目录
- 问题现象:同一请求的不同命运
- 原理解析:什么是TLS指纹?
- 抓包准备:定位目标服务器IP
- Wireshark实战:捕获TLS握手包
- 指纹分析:解读JA3特征值
- 解决方案:模拟浏览器TLS指纹绕过
- 常见问题解答(FAQ)
- 技术总结与趋势展望
1. 问题现象:同一请求的不同命运
首先在火狐浏览器中触发目标接口,右键选择”复制为cURL命令”。将复制的命令分别导入apiPost工具和Python脚本中执行。
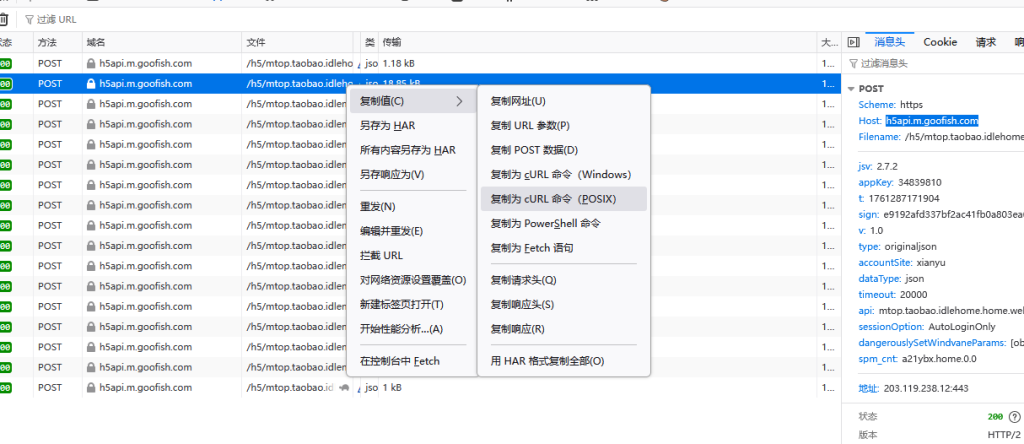
执行后发现,虽然请求参数完全一致,但浏览器重发成功,而apiPost和Python均返回:
FAIL_SYS_ILLEGAL_ACCESS::非法请求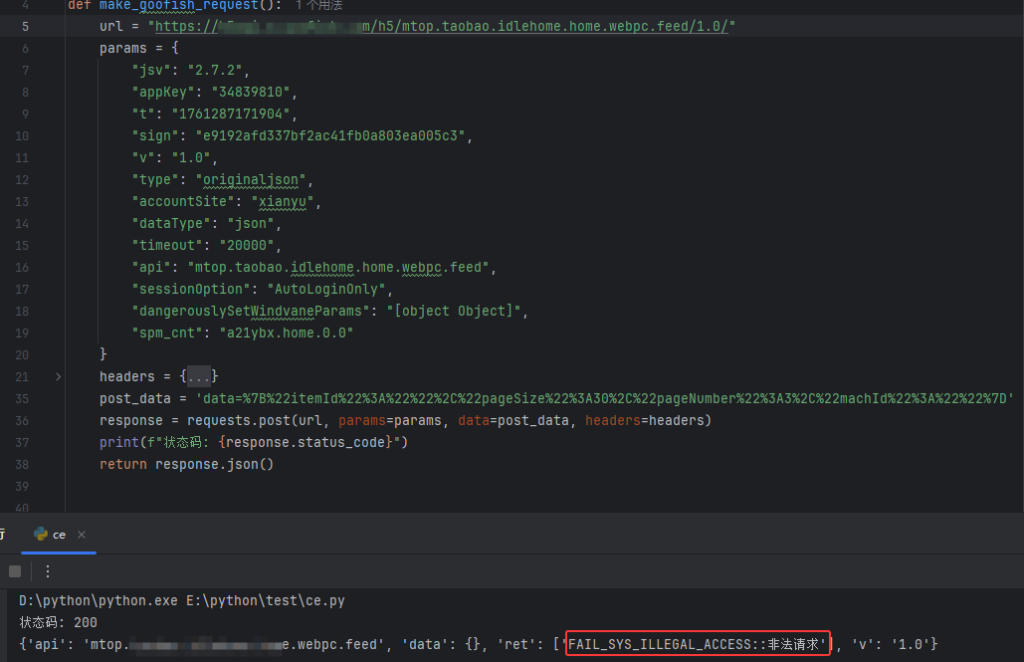
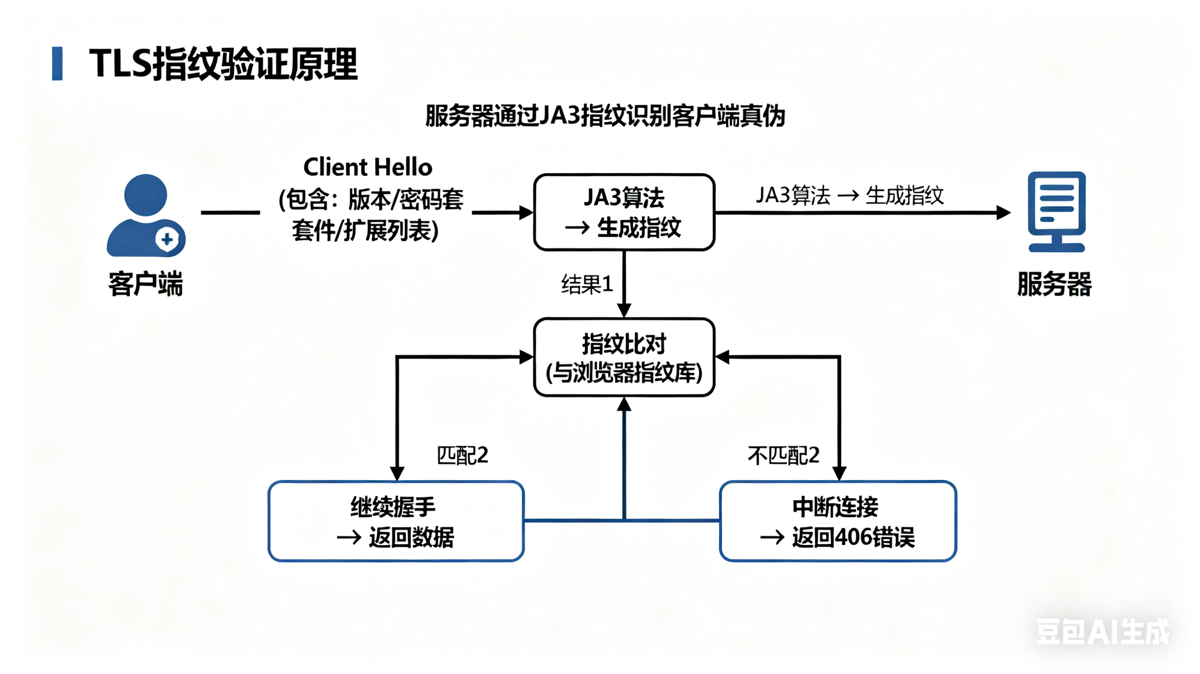
2. 原理解析:什么是TLS指纹?
你可以把网络请求想象成一次寄信。之前我们仿造的是信的内容(请求参数)和信封样式(请求头),但TLS指纹验证检查的是送信人本身的”身份特征”。
当你的程序(无论是浏览器还是Python脚本)试图与服务器建立安全的HTTPS连接时,第一步就是发送一个“打招呼”(Client Hello)的数据包。这个包不仅说要连接,还附带了一份”自我介绍”,里面详细列出了:
- 我支持哪种加密语言(
TLS版本) - 我会多少种密文写法(
加密套件) - 我有哪些特殊技能(
扩展列表)
服务器收到这份”自我介绍”后,会将其中的关键信息按固定格式组合成一个字符串,并通过MD5计算生成一个唯一的“身份ID”,这就是JA3指纹。
不同的客户端(如Chrome、Firefox、Python的Requests库)其”自我介绍”的内容各不相同,因此生成的指纹也完全不同。服务器端维护了一个“合法身份库”(即已知浏览器的指纹),当你的程序指纹不在这个库中时,服务器就会拒绝连接,即使你的请求内容完全正确。
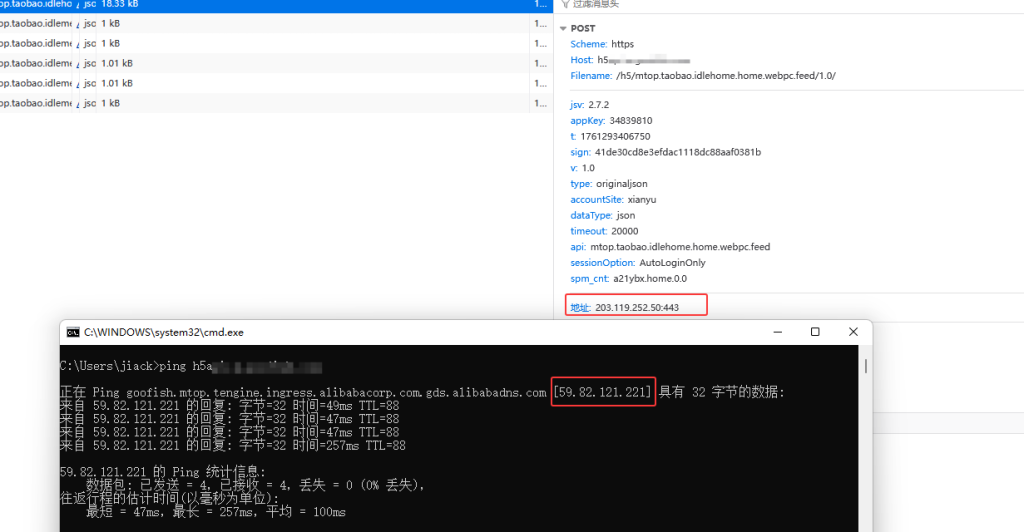
3. 抓包准备:定位目标服务器IP
在浏览器开发者工具中,查看目标接口实际连接的服务器IP地址。由于DNS加速服务的存在,ping命令获取的IP可能与实际连接IP不一致,应以接口请求的地址为准。
4. Wireshark实战:捕获TLS握手包
打开 Wireshark抓包工具,选择合适的网络接口开始抓包。由于TLS握手发生在连接建立的瞬间,我们需要精确控制抓包时机:
- 首先清空
Wireshark的现有捕获数据 - 立即切换到浏览器并刷新某鱼主页
- 快速回到
Wireshark停止捕获
此时会看到大量数据包,为精准定位目标流量,在过滤栏输入:
(ip.addr == 203.119.252.50) and (tls.handshake.type == 1)过滤条件说明:
ip.addr == 203.119.252.50:指定目标服务器IP(请替换为实际IP)tls.handshake.type == 1:专门过滤Client Hello握手包
如果过滤后列表为空,说明Client Hello包已发送完成,需要重新清空捕获并再次刷新页面。

5. 指纹分析:解读JA3特征值
过滤后找到目标数据包,展开TLS协议详情,可以看到JA3指纹检测相关字段:
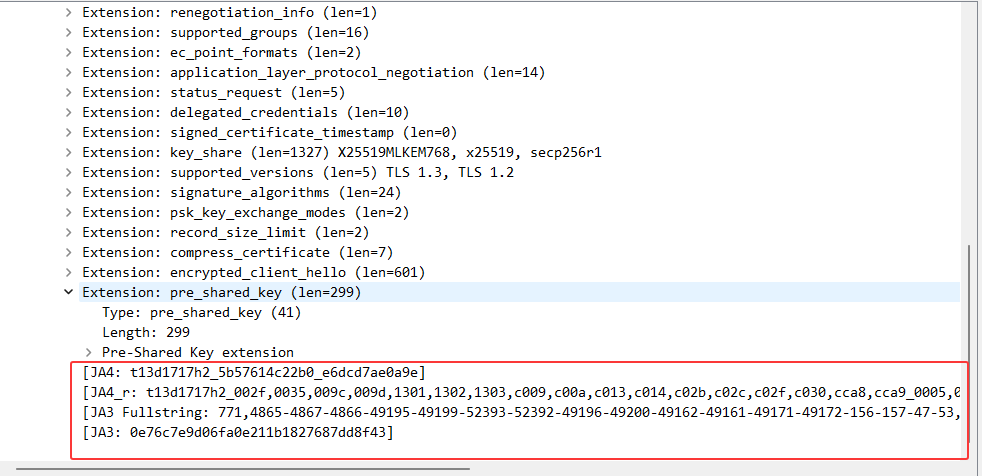
关键字段说明:
JA3 Fullstring:完整的TLS特征字符串,包含所有握手参数JA3:MD5哈希后的32位指纹值,用于快速比对和识别
6. 解决方案:模拟浏览器TLS指纹绕过
基于上述分析,我们需要在Python中模拟浏览器的TLS指纹。推荐使用curl_cffi库,它基于curl并支持模拟不同浏览器的TLS特征。
安装依赖:
pip install curl_cffi示例代码:
from curl_cffi import requests
def make_goofish_request():
url = "https://h5api.m.goofish.com/h5/mtop.taobao.idlehome.home.webpc.feed/1.0/"
params = {
"jsv": "2.7.2",
"appKey": "34839810",
"t": "1761296518013",
"sign": "a98e5a18178608ed9637b3cefb7027ce",
"v": "1.0",
"type": "originaljson",
"accountSite": "xianyu",
"dataType": "json",
"timeout": "20000",
"api": "mtop.taobao.idlehome.home.webpc.feed",
"sessionOption": "AutoLoginOnly",
"spm_cnt": "a21ybx.home.0.0"
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:143.0) Gecko/20100101 Firefox/143.0',
'Accept': 'application/json',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br, zstd',
'Content-type': 'application/x-www-form-urlencoded',
'Origin': 'https://www.goofish.com',
'Connection': 'keep-alive',
'Referer': 'https://www.goofish.com/',
'Cookie': 'tfstk=gULrZRNk443y6bejPKQU_uJJDJjR; cna=PqNhISLD1iICAXzlmBCeG1Qo; xlly_s=1',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-site',
'TE': 'trailers'
}
post_data = 'data=%7B%22itemId%22%3A%22%22%2C%22pageSize%22%3A30%2C%22pageNumber%22%3A2%2C%22machId%22%3A%22%22%7D'
response = requests.post(
url,
params=params,
data=post_data,
headers=headers,
impersonate="firefox" # 模拟Chrome浏览器的TLS指纹
)
print(f"状态码: {response.status_code}")
return response.json()
if __name__ == "__main__":
result = make_goofish_request()
print(result)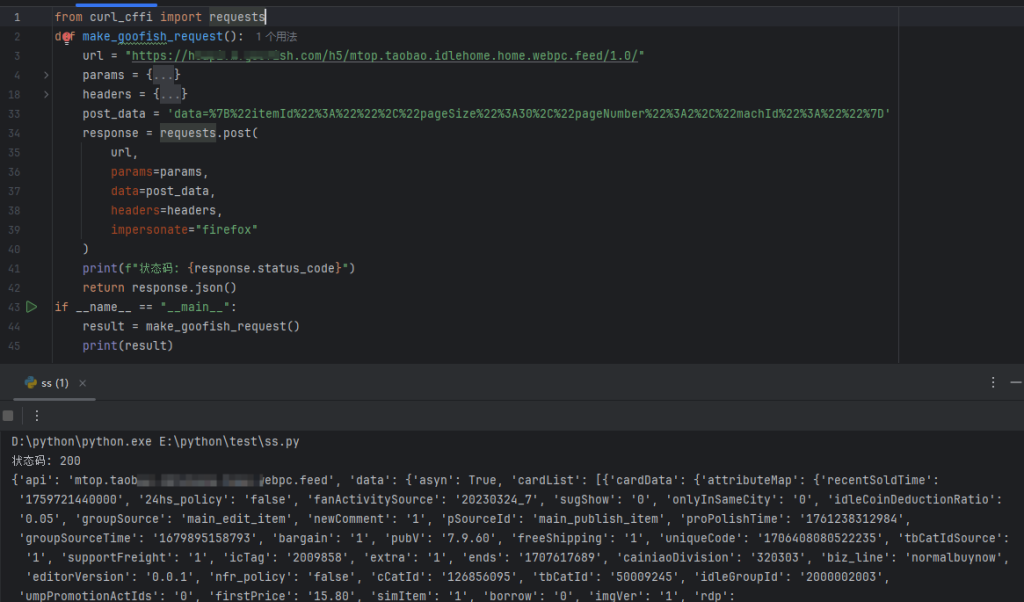
7. 常见问题解答(FAQ)
- Q:为什么之前能用的爬虫突然失效了?
A:很可能是网站升级了防护策略,加入了TLS指纹验证。传统的UA伪装已不足以绕过此类检测。 - Q:除了curl_cffi,还有其他解决方案吗?
A:有的。还可以使用pyhttpx、tls_client等库,或者通过修改系统底层SSL配置来实现。 - Q:TLS指纹会变化吗?
A:会的。浏览器版本更新会改变其TLS指纹,因此需要定期更新模拟的浏览器版本。 - Q:所有网站都会检测TLS指纹吗?
A:不是。目前主要是一些大型网站或对安全要求较高的平台会使用此技术。
8. 技术总结与趋势展望
通过本次实战,我们见证了反爬虫技术的又一次进化。当我们在应用层的斗争日趋白热化时,战场正在向更底层的网络协议栈延伸。TLS指纹验证标志着一个重要的转折点:逆向工程的核心,正在从”理解业务逻辑”转向”模拟系统行为”。
这要求我们不仅要能解密前端的加密算法,更要能深度模仿一个真实浏览器的完整网络栈特征。展望未来,单一的对抗手段将越来越无力,下一个前沿必将是浏览器环境虚拟化、协议栈仿真、行为指纹对抗等技术的综合运用。掌握网络层分析与TLS指纹的绕过,只是我们踏入这个全新战场的第一个台阶。
下期预告:我们将深入探索Wireshark的高级应用,掌握精准协议过滤与流量分析技巧,为应对更复杂的网络层对抗打下坚实基础。本文由林石工作室提供技术支持,转载请注明出处。
大佬牛,新手入门学到了很多